


 Share on Twitter
Share on Twitter
Let’s dig into how we can use Machine Learning to do some college basketball predication. In the last post we discussed how to scrap the data into a SQL database. Now let’s open up that dataset and do some analytics. I will be using Microsoft’s Azure machine learning to process the data but feel free to use any tool you would like. Hopefully, I’ll give you a few ideas on how to get started and show you what worked for me and what didn’t.
Azure Machine Learning has a free trial. Even if you find you have to sign up, the size of the dataset is so small it’s really not much money.
It’s probably a good time to add a disclaimer that I am not an expert in Machine Learning. I’m really not an expert in Basketball for that matter. However, I’ve found this to not be a big limitation to still having some fun with the data. Even if you find yourself in the same boat, the tooling that is available now is fantastic and makes it possible to dive in regardless.
If you haven’t read the previous post we pulled the data at the player level for each game. This is a pretty excellent level of granularity so I wanted to try and leverage this as much as I can. Team stats are just an aggregate of this data which may hide some of the possible relationships that are occurring. We need to organize the data in such a way that we have the game result lined up with all the different stats that should help predict that result. Think of this as one row of data we will feed into our machine learning engine.
| Game Result | Player Stats for Team 1 | Player Stats for Team 2 |
|---|---|---|
| Game 1 Winner | … | … |
| Game 2 Winner | … | … |
| Game 3 Winner | … | … |
The idea is to send half of this data through various machine learning models to train them. The algorithms will use different methods to determine which stats have the largest contribution to predicting the result. Obviously, the more data we have the better. What’s interesting about this is the model will decide what’s important based on the trends that occur in the data. Remember how I said I don’t know basketball very well? Well, its ok because the model does the work, I just need to give it as much as possible to work with. After each model is trained we can evaluate the accuracy by feeding the remaining half of data through and score the performance. The tooling in Azure ML will provide back the stats on how accurate the model was at predicting this second half data set of games.
Before I tell you the approach I used, keep in mind that this is where you can really deviate. There is no right answer on this. I choose to aggregate a player’s performance in 4 games prior to the game they are about to play. It’s important not to use a player’s performance in the actual game we are trying to predict since I want to run the model against games I don’t have data for. Next I lined of the top 8 players based on minutes played in those previous 4 games. The idea is that the model can compare the player performance head to head between the teams. The data set looks something like this:
| Game Result | Player 1 Stats for Team 1 | Player 2 Stats for Team 1 | … | Player 1 Stats for Team 2 | Player 2 Stats for Team 2 | … |
|---|---|---|---|---|---|---|
| Game 1 Winner | … | … | … | … | … | … |
| Game 2 Winner | … | … | … | … | … | … |
| Game 3 Winner | … | … | … | … | … | … |
Quick side note, I aggregated this data using SQL views. To use Azure Machine Learning you need to get this data into SQL Azure. SSIS can be helpful for moving data from one SQL database to another.
Time to open up Azure Machine Learning! This toolset uses drag and drop modules for creating workflows for the data.
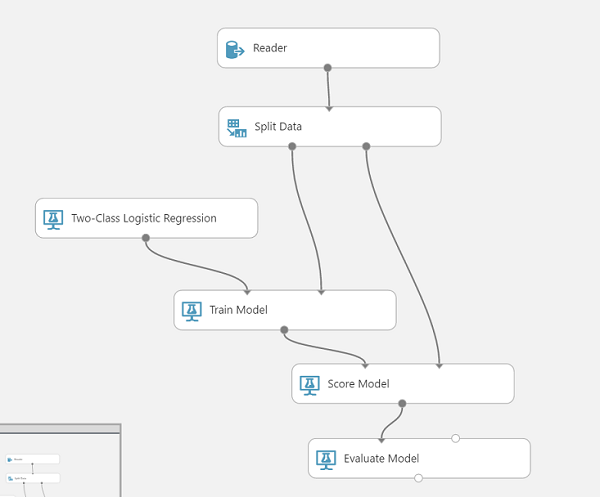
The first module imports in our dataset from a SQL Azure database. You can enter the SQL query here along with the connection details. Next, we split this dataset in half. Half will be used to train our model, half for scoring which is also shown. The training module requires us to specify which column it is that contains the game result. You will know you messed this up if the results come in at 100% accuracy (because it used the result to determine the result!). Finally, we evaluate the performance of the model.
I only show one model type, the Two-Class Logistic Regression model. You can and should try other models to fit the data. Experiment with this part to see what give the best result. In my case I received the following output from the evaluation:
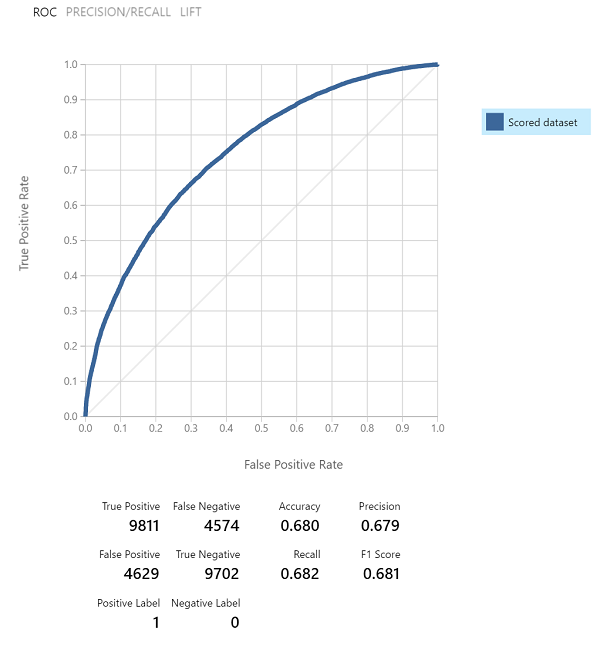
Now I know what you’re thinking, 68% isn’t very good right? Well, it’s not bad and that’s sort of how it goes with predictions in sports. Want to see how it translates to a bracket? Below is my bracket from the 2016 tournament:

Notice that I was in fact 68% accurate on the first round of games! The problem is the miss predicted games start to stack up and you can see everything starts to fall apart the second round. I do want credit that I out predicted Bing predications (although that was not very difficult to do this year). I really look forward to what you guys find, please post your ideas/results!